Porovnání dvou seznamů (listů, tabulek) je v praxi velmi frekventovaným tématem. Nejčastější úlohou je tvorba nového ceníku na základě stávajícího ve spojení s aktualizovaným seznamem dodavatele. S čím se můžeme setkat:
a) U produktu došlo k pozastavení (ukončení) výroby (tj. produkt z našeho seznamu již nenacházíme v seznamu dodavatele)
V tom případě probíhá výprodej a cena zůstává stejná až do vyprodání zásob. Po té by měl být produkt odstraněn z výběru. Ne úplně fyzicky, spíš doporučuji jakousi archivaci z důvodu zachování historie a kupříkladu celoročního vyhodnocení prodeje.
b) U produktu došlo ke změně ceny (tj. produkt se nachází v našem seznamu i v seznamu dodavatele)
Cena produktu se pravděpodobně přizpůsobí nové ceně od dodavatele.
c) Nový produkt (produkt se nachází pouze v seznamu dodavatele)
Novinku je potřeba zařadit do stávajícího seznamu včetně zaváděcí ceny.
Odhadem 80 % běžných uživatelů znalých práce na listu se při porovnávání seznamů obrací na funkce. Pravděpodobně první na ráně je v Excelu funkce SVYHLEDAT. Následující snímek (viz také příloha) ukazuje řešení základních požadavků.

Uvedené vzorce nepředstavují žádné geniální know-how, zkrátka dělají, co mají. Funkce JE.NEDEF, resp. IFERROR ošetřují stavy, kdy jedna či druhá vyhledávací funkce nenajde položku v seznamu. Funkce ŘÁDEK poslouží k dopočtu pořadí hledané položky vůči počátku listu (A1). Ačkoliv pracuje s oblastí, vrátí řádek její první buňky. Pojmenované oblasti lehce zpřehledňují celý zápis, nejsou nutné.
Tím bychom mohli skončit, nicméně posuneme řešení na vyšší úroveň. Tu reprezentuje databázový přístup k seznamům. I k sešitům, listům a seznamům na nich se dá přistupovat prostřednictvím jazyka SQL. My se budeme držet Excelu 2010, ve kterém máme k dispozici k opracování dat pazourek, tedy Microsoft Query.
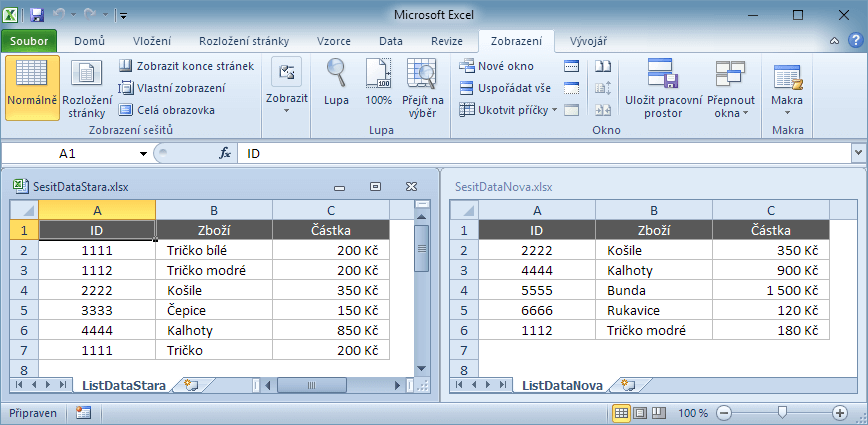
Porovnání probíhá na základě jedinečného kódu produktu (klíče), nikdy ne na základě textového popisu (přejmenovaný produkt, chyby v diakritice, nadbytečné mezery, …). I tak by prvním krokem měla být kontrola stávajícího seznamu (v příkladu viz duplicita trička s kódem 1111).
Dotazy do seznamů jsem rozdělil na dva poddotazy slovně asi takto:
A) „Vezmi všechny produkty stávajícího seznamu, a pokud k nim existují nové ceny, doplň je.“
B) „Pokud se v dodaném seznamu nacházejí nové produkty, doplň je do stávajícího i s cenou.“
Tento článek si neklade za cíl vás naučit pracovat v editoru Micorosft Query, proto jen letmý textový postup pro první poddotaz.
1) Data / Z jiných zdrojů / Z aplikace Microsoft Query / dialog Zvolit zdroj dat / záložka Databáze, Excel Files
2) Dialog Vybrat sešit, Zobrazit soubory typu: Všechny soubory (aby byly vidět i novodobé sešity s příponou XLSX) a v části Název databáze vybrat sešit se stávajícím seznamem.
3) Dialog Průvodce dotazem, převést sloupce (pokud nevidíte žádnou dostupnou tabulku, pod tlačítkem Možnosti zaškrtněte Systémové tabulky) a v poslední části dialogu vybrat volbu Zobrazit data nebo upravit dotaz v aplikaci Microsoft Query.
4) V okně Microsoft Query zvolit Tabulka / Přidat tabulky, a vybrat sešit s dodaným seznamem (rozbalovací nabídka napravo od popisu Sešit, tlačítko Přidat).
5) Ze zástupců obou seznamů přetažením položek do tabulkové části poskládat dotazované sloupce a případně přejmenovat hlavičky.
6) Přetáhnout položku ID ze zástupce stávajícího seznamu nad položku ID v zástupci dodaného seznamu, poklepat na vzniklou spojnici, zvolit typ vazby a potvrdit výběr tlačítkem Přidat. Jsem si vědom tohoto, že přesně tento bod je překážkou, přes kterou se řada uživatelů špatně přenáší (spojování tabulek typu INNER JOIN, LEFT JOIN, …).
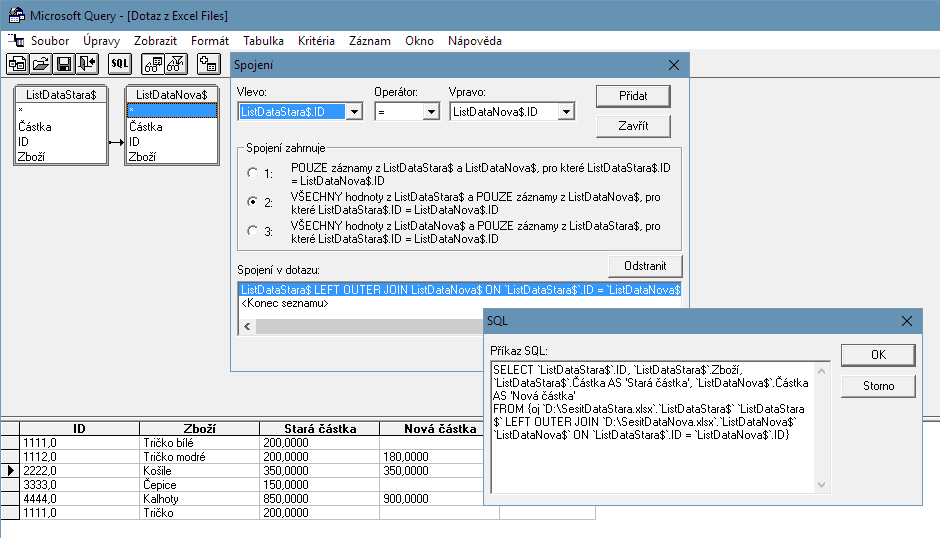

Nyní si dovolím malou odstávku tématu a povzdechnutí…
Před sepsáním tohoto článku jsem několik hodin řešil, proč mi Microsoft Query špatně zobrazuje české znaky.
Nějaký dobrák počeštil designer v Microsoft Query natolik, že přimotal český překlad i do klíčových slov jazyka SQL. Pamatuji si na kurz, kdy se jeho účastníci chtěli naučit pracovat v Microsoft Query. A chápal jsem jejich finální „no to ne, to si radši dotazy a pohledy připravíme v Accessu“.
I když Microsoft Query umí pracovat s definovanými názvy, ignoruje Tabulky.
Excel sám neví, které chtít uvozovky v popiscích sloupců a textových řetězcích (zpětné, jednoduché, dvojité). Pro existující názvy sloupců používá jednoduché zpětné, pro textové řetězce snad očekává jednoduché uvozovky, nicméně ty pak viditelně promítá do hlavičky na listu. A editor Microsoft Query má problémy jak s jednoduchými, tak s dvojitými.
Pro Microsoft Query nebyla nikdy pořádně dokončena nápověda a tak leckdy hádáme, co použít za funkce, datové typy, a jaká syntaxe je platná. Na hromadě leží pojmy jako Microsoft Jet, ADODB a nezřídka budeme mít pocit, že se pohybujeme ve VBA (funkce IIf a jiné).
Humor nás definitivně přejde v případě, že zdrojem dat jsou právě listy Excelu. Čeká nás peklo s rozpoznáváním typu hodnot ve sloupcích (viz pojem IMEX).
Excel 2010 navíc nezvládá běžným způsobem importovat časové údaje (musí se převádět na desetinné číslo).
Prostě žůžo dobrodrůžo.
Možná i proto druhý poddotaz a další úpravy už zpravidla řeším rozkopírováním a úpravou přímo v Excelu a jeho dialogu Vlastnosti připojení (do kterého se proklikávat co půl minuty při ladění je také radost).
Ačkoliv nejsem masochista, úlohu jsem si před spojením poddotazů ještě o trochu ztížil. Jednak je pro další práci vhodnější mít nové ceny ve stejném sloupci, jednak jsem chtěl slovně okomentovat nedohledané produkty.
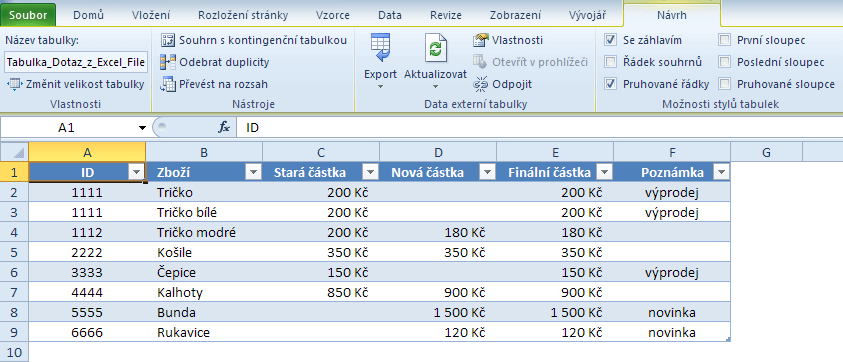
Finální SQL dotaz tedy může vypadat nějak takto (nejsem databázovým expertem, proto mi prosím případně odpusťte složitější formu):
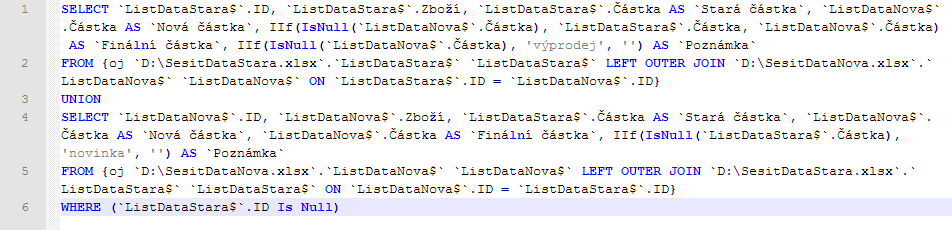
Sloučení poddotazů v jeden zajišťuje klíčové slovo Union. Bez něj se horko těžko obejdeme i v případě, že potřebujeme prosté spojení datových zdrojů stejné struktury v jeden. Tuhle jednoduchou věc neumí ani souhrny, ani kontingenční tabulky, jež musí za každou cenu nad daty provádět nějakou matematickou operaci.
Tip: SQL dotaz, který vrátilo Microsoft Query, si zkopírujte kupříkladu do textového editoru Notepad++ a zvolte syntaxi SQL. Klíčová slova se obarví a s textem je pak snazší pracovat (viz i obrázek výše).
Příloha
excel-porovnani-seznamu.zip