Již vícekrát se mi dostal do ruky výstup se záznamy uspořádanými do bloků pod sebou v jednom sloupci a cílem byla jejich transformace do přijatelné (databázové) podoby (tj. seznam), vhodné pro filtrování a třeba jako zdroj pro kontingenční tabulku – viz obrázek. Pracovně tomuto typu úlohy říkám „věšení prádla“.
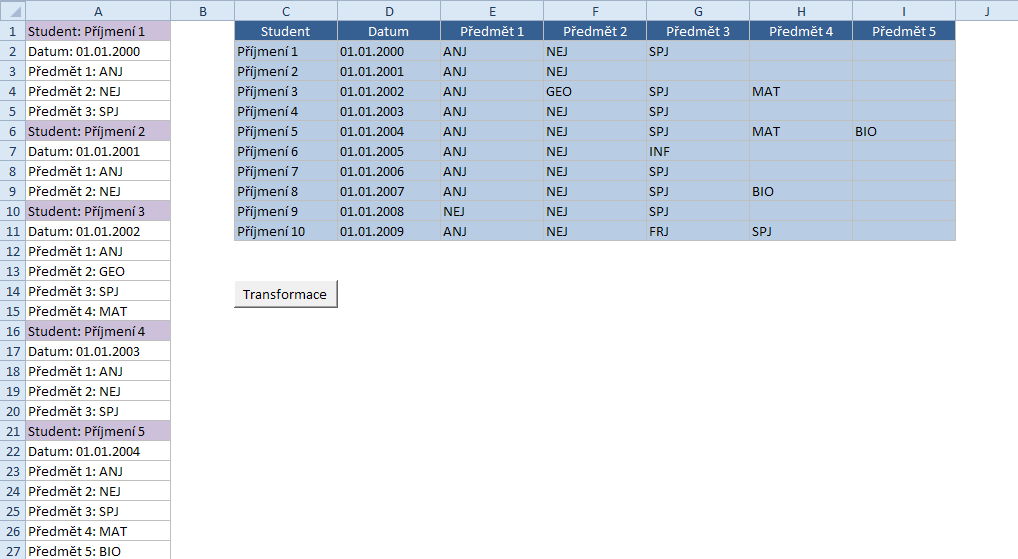
Bloky nejsou stejně dlouhé (vysoké), tj. záznamy nemají vždy vyplněné všechny položky. Pro zpracování potřebujeme znát maximální počet položek v bloku (budoucích sloupců, tj. polí) a počáteční položku nového bloku. Nabízím následující způsob řešení:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | Option Base 1 Const strOddelovacPoleHodnota As String = ":" Sub TransformaceDat() Dim rngData As Range Dim rngBunka As Range Dim aPole Dim astrPolozky Dim strPrvniPolozka As String 'definice polí astrPolozky = Array("Student", "Datum", "Předmět 1", "Předmět 2", _ "Předmět 3", "Předmět 4", "Předmět 5") 'referenční pole (začíná jím blok) strPrvniPolozka = astrPolozky(1) 'zdrojová data Set rngData = Range(Range("A1"), Range("A1").End(xlDown)) 'počet sloupců iPocetSloupcu = UBound(astrPolozky) 'počet bloků (výskytů referenční položky) iPocetBloku = WorksheetFunction.CountIf(rngData, "=" & strPrvniPolozka & "*") ReDim aPole(1 To iPocetBloku, 1 To iPocetSloupcu) 'pro každou buňku For Each rngBunka In rngData 'rozdělení buňky na název pole a jeho hodnotu aPoleBunka = Split(rngBunka.Text, strOddelovacPoleHodnota) 'pozice nalezeného pole 'ořez od mezer před a za textem iPole = Application.Match(WorksheetFunction.Trim(aPoleBunka(0)), _ astrPolozky, 0) If iPole = 1 Then 'zjištěno pole Student ... nový řádek iZaznam = iZaznam + 1 End If 'ořez od mezer před a za textem aPole(iZaznam, iPole) = WorksheetFunction.Trim(aPoleBunka(1)) Next rngBunka 'naplnění hlavičky Range("C1").Resize(1, iPocetSloupcu) = astrPolozky 'naplnění oblasti buněk Range("C2").Resize(iPocetBloku, iPocetSloupcu) = aPole End Sub |
Možná vás napadlo použít Data / Text do sloupců k rozdělení názvu položky od její hodnoty na základě dvojtečky. Ano, je to možné, ovšem větší smysl by to mělo pouze v případě, že byste chtěli poté první sloupec filtrovat na jedinečné položky a zjišťovat onen maximální počet typů položek v bloku (záznamu). Otázkou je, jestli daný vzorek dat obsahuje všechny existující. Já jsem pro to raději zjistit daný údaj od zadavatele a v kódu s ním již napevno počítat (viz astrPolozky).
Příklad ke stažení:
excel-rozradit.zip